Gathering and preparing data for training can be a time-consuming process. In the world of machine learning, data is the foundation upon which successful models are built. Azure offers a powerful solution by combining Azure Data Factory and Azure Machine Learning Studio to automate the creation of datasets and the subsequent training pipeline. In this blog post, we’ll guide you through scheduling the creation of a machine learning dataset, storing it in Azure Blob Storage, and triggering the training pipeline using Azure Data Factory.
Setting Up the Environment
Before diving into the steps, ensure you have the necessary components set up:
- Azure Data Factory: Create an instance of Azure Data Factory if you haven’t already. Azure Data Factory is a cloud-based data integration service that allows you to create, schedule, and manage data pipelines.
- Azure Machine Learning Studio: Set up an Azure Machine Learning workspace and publish a pipeline that defines your training workflow.
- Azure Blob Storage: Create a storage account to store the generated dataset and any other relevant files.
- Service Principal: Ensure you have a service principal with the appropriate permissions. The service principal should have the Contributor Role on the Azure Machine Learning Workspace, a Storage Blob Data Contributor Role on the Azure Data Lake Storage Account associated with Azure Machine Learning or Blob Data Contributor Role if the dataset is stored in a different Storage Account.
- In the Data Factory Linked Services menu, add the Azure Machine Learning service to the Data Factory.
Step-by-Step Guide
1. Dataset Creation with Data Factory
Let’s begin by creating a Data Flow in Azure Data Factory to generate the machine learning dataset:
- Log in to your Azure portal and navigate to your Azure Data Factory instance.
- Create a new Data Flow that transforms and processes your data as needed.
- Configure the data source, transformations, and data sink (Azure Blob Storage).
- In the data sink settings, specify the target Blob Storage container where the dataset will be stored.
- Inside your last “Sink” Step, Configure the Blob Storage settings, providing the connection details and the target container within your storage account.
For me, the result looks something like this:

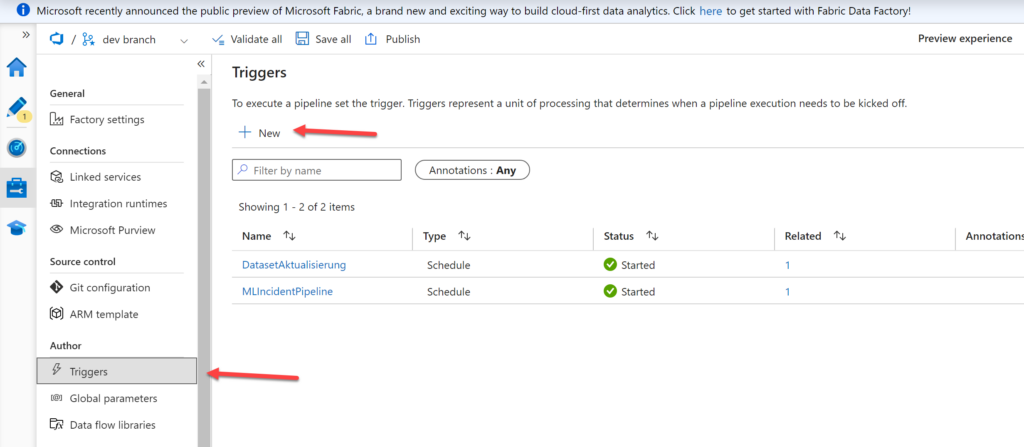
2. Scheduling Dataset Creation
To schedule the dataset creation process, set up a trigger in Azure Data Factory:
- In your Data Factory instance, navigate to the Manage -> Author section.
- Create a new trigger that specifies when the dataset creation process should run. Set an appropriate recurrence schedule. It’s recommended that you try to keep the regeneration only as often as you want to retrain your pipeline. I’d suggest once a week.
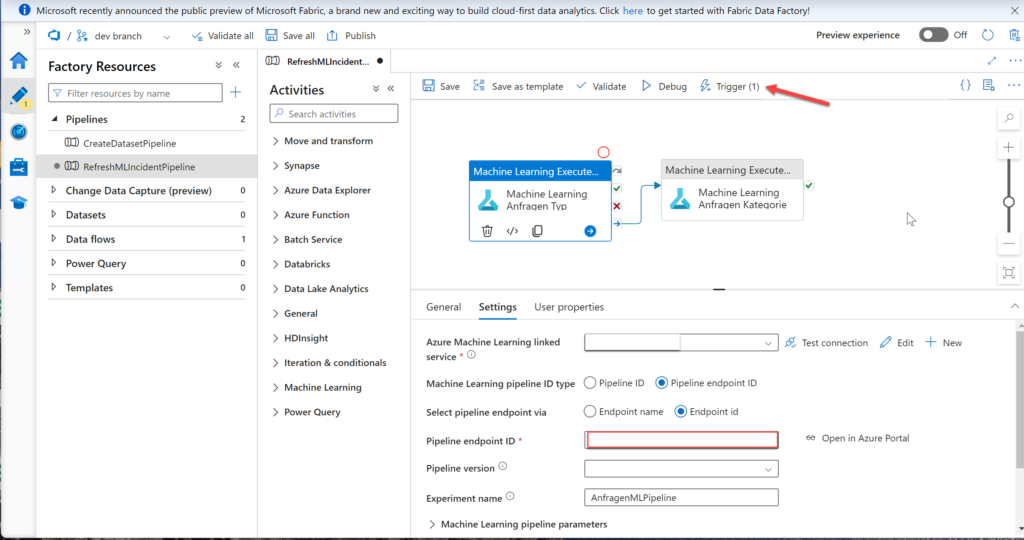
3. Triggering the Machine Learning Pipeline
After allowing some time between dataset creation and pipeline execution, it’s time to trigger the training pipeline:
- In your Azure Data Factory, create a new pipeline that uses the “Machine Learning Execution” activity.
- To get it to work, you will need to provide the published pipeline ID as a parameter.
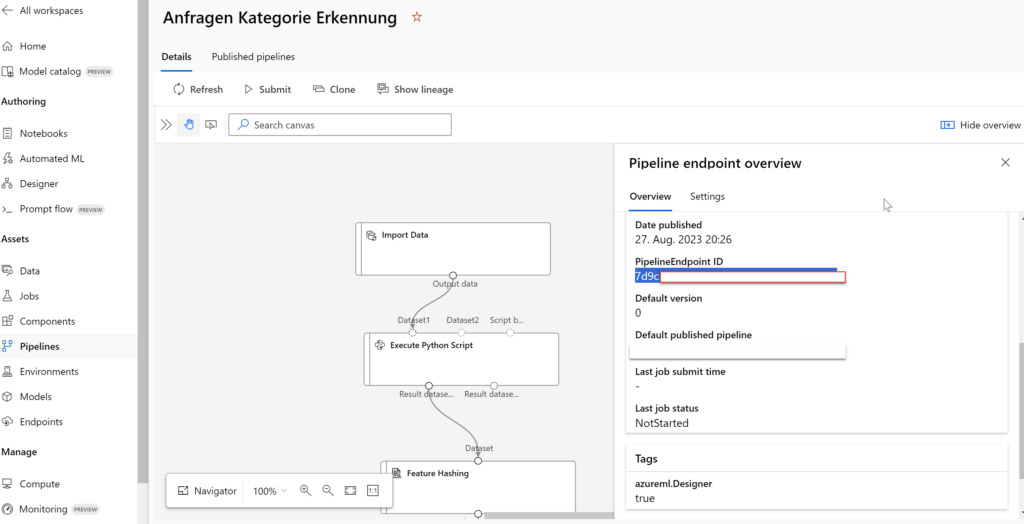
The Pipeline ID can be found in your Pipeline on the “Pipeline endpoint overview” card:
4. Ensuring Service Principal Permissions
For the seamless execution of this automated workflow, ensure that your service principal has the required permissions:
- In your Azure portal, navigate to the Azure Machine Learning workspace.
- Assign a Contributor Role to the service principal (of the Data Factory) so it can access your Pipeline.
- If the dataset or other resources are in a different Storage Account, ensure that the service principal has the necessary Blob Data Contributor Role for that Storage Account.
- Everything is set up now and the Pipelines should trigger one after another
5. Conclusion
By combining the capabilities of Azure Data Factory and Azure Machine Learning Studio, you can automate the process of creating datasets, training machine learning models, and orchestrating complex workflows. The seamless integration of these Azure services simplifies the pipeline, reduces manual intervention, and enhances the efficiency of your machine learning projects. With proper scheduling, triggering, and permissions management, you can build and deploy models with confidence, knowing that your data workflows are optimized and reliable.